
Introduction
Coban, Grab’s real-time data streaming platform team, has been building an ecosystem around Kafka, serving all مینون verticals. Along with stability and performance, one of our priorities is also cost efficiency.
In this article, we explain how the Coban team has substantially reduced Grab’s annual cost for data streaming by enabling Kafka consumers to fetch from the closest replica.
Problem statement
The مینون platform is primarily hosted on AWS cloud, located in one region, spanning over three Availability Zones (AZs). When it comes to data streaming, both the Kafka brokers and Kafka clients run across these three AZs.
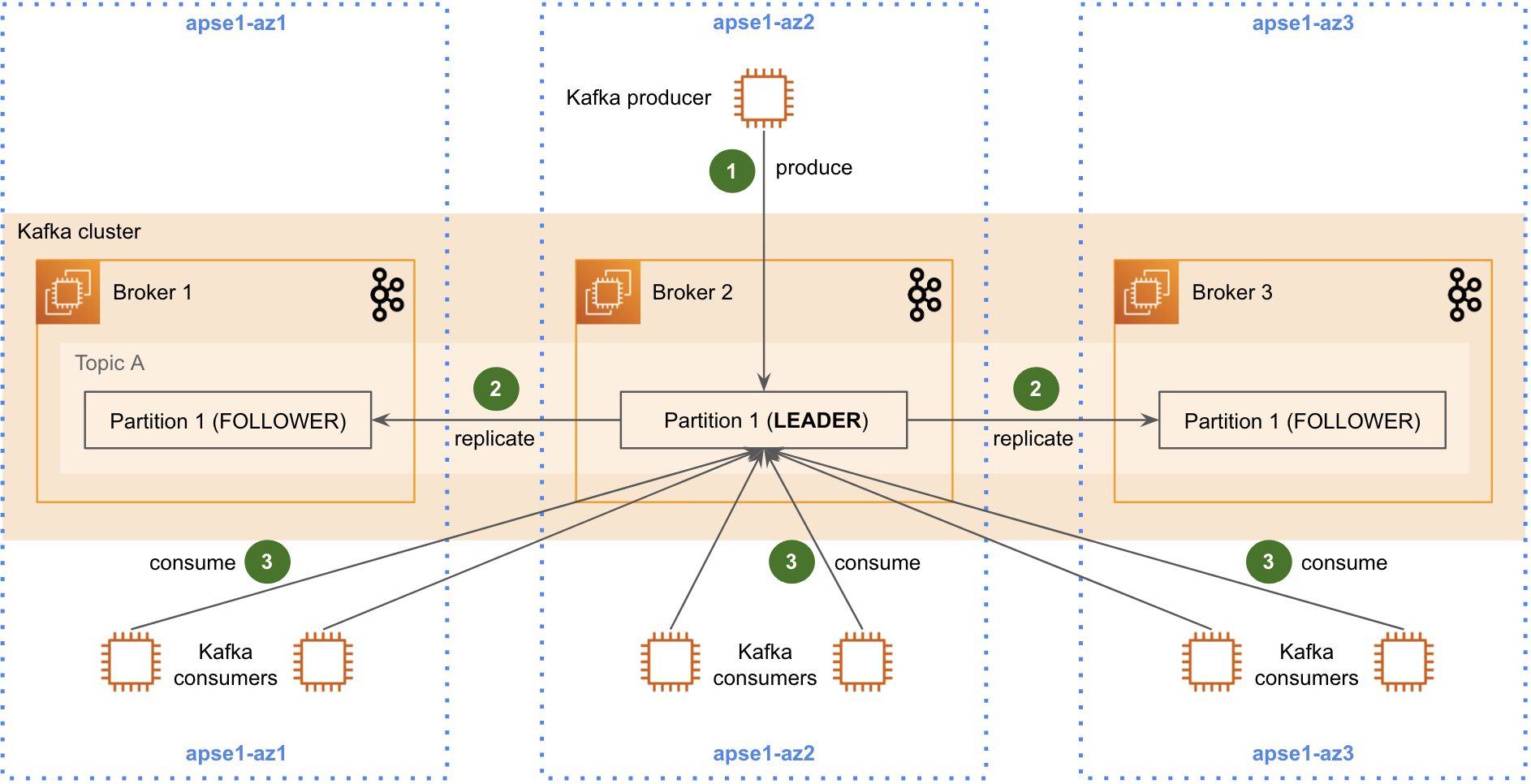
Figure 1 shows the initial design of our data streaming platform. To ensure high availability and resilience, we configured each Kafka partition to have three replicas. We have also set up our Kafka clusters to be rack-aware (i.e. 1 “rack” = 1 AZ) so that all three replicas reside in three different AZs.
The problem with this design is that it generates staggering cross-AZ network traffic. This is because, by default, Kafka clients communicate only with the partition leader, which has a 67% probability of residing in a different AZ.
This is a concern as we are charged for cross-AZ traffic as per AWS’s network traffic pricing model. With this design, our cross-AZ traffic amounted to half of the total cost of our Kafka platform.
The Kafka cross-AZ traffic for this design can be broken down into three components as shown in Figure 1:
- Producing (step 1): Typically, a single service produces data to a given Kafka topic. Cross-AZ traffic occurs when the producer does not reside in the same AZ as the partition leader it is producing data to. This cross-AZ traffic cost is minimal, because the data is transferred to a different AZ at most once (excluding retries).
- Replicating (step 2): The ingested data is replicated from the partition leader to the two partition followers, which reside in two other AZs. The cost of this is also relatively small, because the data is only transferred to a different AZ twice.
- Consuming (step 3): Most of the cross-AZ traffic occurs here because there are many consumers for a single Kafka topic. Similar to the producers, the consumers incur cross-AZ traffic when they do not reside in the same AZ as the partition leader. However, on the consuming side, cross-AZ traffic can occur as many times as there are consumers (on average, two-thirds of the number of consumers). The solution described in this article addresses this particular component of the cross-AZ traffic in the initial design.
Solution
Kafka 2.3 introduced the ability for consumers to fetch from partition replicas. This opens the door to a more cost-efficient design.
Step 3 of Figure 2 shows how consumers can now consume data from the replica that resides in their own AZ. Implementing this feature requires rack-awareness and extra configurations for both the Kafka brokers and consumers. We will describe this in the following sections.
The Coban journey
Kafka upgrade
Our journey started with the upgrade of our legacy Kafka clusters. We decided to upgrade them directly to version 3.1, in favour of capturing bug fixes and optimisations over version 2.3. This was a safe move as version 3.1 was deemed stable for almost a year and we projected no additional operational cost for this upgrade.
To perform an online upgrade with no disruptions for our users, we broke down the process into three stages.
- Stage 1: Upgrading Zookeeper. All versions of Kafka are tested by the community with a specific version of Zookeeper. To ensure stability, we followed this same process. The upgraded Zookeeper would be backward compatible with the pre-upgrade version of Kafka which was still in use at this early stage of the operation.
- Stage 2: Rolling out the upgrade of Kafka to version 3.1 with an explicit backward-compatible inter-broker protocol version (
inter.broker.protocol.version). During this progressive rollout, the Kafka cluster is temporarily composed of brokers with heterogeneous Kafka versions, but they can communicate with one another because they are explicitly set up to use the same inter-broker protocol version. At this stage, we also upgraded Cruise Control to a compatible version, and we configured Kafka to import the updatedcruise-control-metrics-reporterJAR file on startup. - Stage 3: Upgrading the inter-broker protocol version. This last stage makes all brokers use the most recent version of the inter-broker protocol. During the progressive rollout of this change, brokers with the new protocol version can still communicate with brokers on the old protocol version.
Configuration
Enabling Kafka consumers to fetch from the closest replica requires a configuration change on both Kafka brokers and Kafka consumers. They also need to be aware of their AZ, which is done by leveraging Kafka rack-awareness (1 “rack” = 1 AZ).
Brokers
In our Kafka brokers’ configuration, we already hadbroker.rackset up to distribute the replicas across different AZs for resiliency. Our Ansible role for Kafka automatically sets




{kind=link}